PS:因为TensorFlow的官网教程里有,所以就顺带了解一下NLP,但不做编程训练,我还是要主攻图像
这篇博文比较清楚得解释了word2vec模型是个什么 :https://zhuanlan.zhihu.com/p/26306795
一、word2vec模型是什么
word2vec模型:该模型是用于通过学习得到文字符号的向量表示,即是模型训练完后神经网络的权重。
1. NLP (自然语言处理)
PS:NLP具体是做什么工作的 https://www.zhihu.com/question/19895141/answer/149475410
1.句法语义分析:对于给定的句子,进行分词、词性标记、命名实体识别和链接、句法分析、语义角色识别和多义词消歧。
2.信息抽取:从给定文本中抽取重要的信息,比如,时间、地点、人物、事件、原因、结果、数字、专有名词等等
3.文本挖掘(或者文本数据挖掘):包括文本聚类、分类、信息抽取、摘要、情感分析以及对挖掘的信息和知识的可视化、交互式的表达界面。
4.机器翻译:把输入的源语言文本通过自动翻译获得另外一种语言的文本。根据输入媒介不同,可以细分为文本翻译、语音翻译、手语翻译、图形翻译等。
5.信息检索:对大规模的文档进行索引。可
6.问答系统: 对一个自然语言表达的问题,由问答系统给出一个精准的答案。
2. 词嵌入( word embedding)
词嵌入( word embedding) :将词语转换为数值形式
举个简单例子:如果需要判断一个词的词性,是动词还是名词。
用机器学习的思路解决,通过一系列样本(x,y), x 是词语,y 是它们的词性,构建 f(x):x->y 的映射。
但数学模型 f 只接受数值型输入,而 NLP 里的词语是符号形式(比如中文、英文、拉丁文),所以需要把符号转换成数值,或者说是嵌入到一个数学空间里,这种嵌入方式就叫词嵌入(word embedding)。
3. one hot
one hot:属于词嵌入( word embedding)的一种,当某一位为一的时候其他位都为零,这个向量就代表一个单词
缺点:
- 由于向量长度是根据单词个数来的,如果有新词出现,这个向量还得增加
- 主观性太强
- 很难计算单词之间的相似性
4. Word2vec
Word2vec:属于词嵌入( word embedding)的一种,通过神经网或者深度学习对词进行训练,得到一个指定维度的向量,将练完后模型参数作为输入词语的向量化表示
在 NLP 中,把 x 看做一个句子里的一个词语,y 是这个词语的上下文词语,那么这里的 f,便是 NLP 中经常出现的『语言模型』(language model),这个模型的目的,就是判断 (x,y) 这个样本,是否符合自然语言的法则,即词语x和词语y放在一起,是不是人话。
Word2vec 正是来源于这个思想,它只关心模型训练完后模型参数(这里特指神经网络的权重),并将这些参数,作为输入 x 的某种向量化的表示,这个向量便叫做词向量,而这里的向量其实是经过降维。
二、语言模型
Word2vec是种高效率词嵌套学习的预测模型,其两种变体为:
- Skip-gram 模型:将一个词语作为输入,来预测它周围的上下文
- CBOW 模型:将一个词语的上下文作为输入,来预测这个词语本身
1. Skip-gram 和 CBOW 的简单情形
用当前词 x 预测它的下一个词 y(Skip-gram)
用上下文词 x 预测当前词 y(CBOW)
(1)one-hot encoder: x 的输入形式
假设全世界所有的词语总共有 V 个,这 V 个词语有自己的先后顺序,假设『吴彦祖』这个词是第1个词,就可以表示为一个 V 维全零向量、把第1个位置的0变成1,『我』这个单词是第2个词,表示为 V 维全零向量、把第2个位置的0变成1。每个词语都可以找到属于自己的唯一表示。
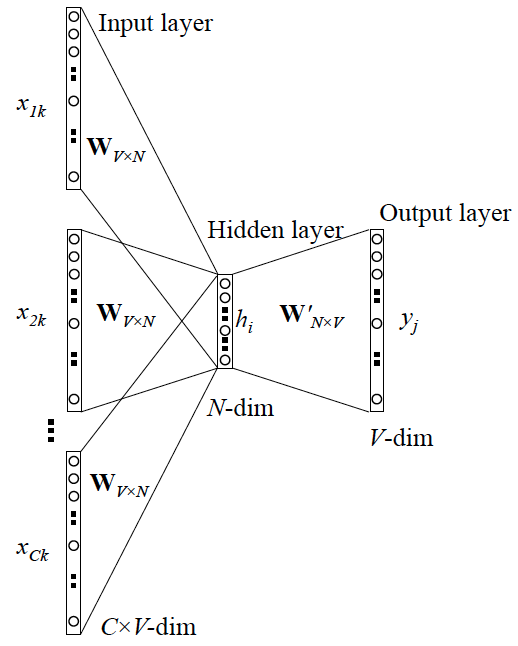
(2)Skip-gram 的网络结构:x 就是 one-hot encoder 形式的输入,y 是在这 V 个词上输出的概率
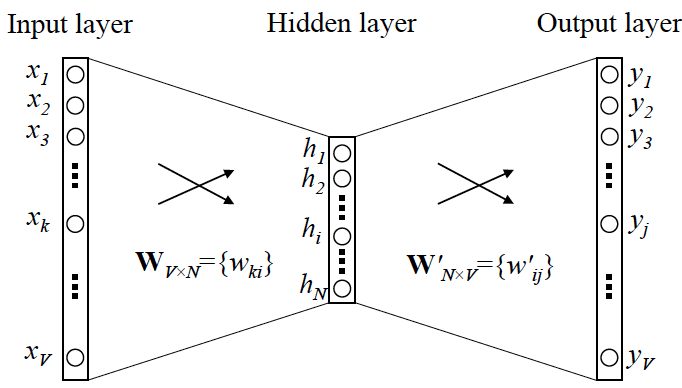
(3)Word2vec :one-hot encoder形式的输入x,存在与这个位置相对应的被激活的权重vx
当模型训练完后,最后得到的其实是神经网络的权重,比如现在输入一个 x 的 one-hot encoder [1,0,0,…,0],对应词语『吴彦祖』,则在输入层到隐含层的权重里,只有对应 1 这个位置的权重被激活,从而这些权重组成一个向量 vx 来表示x,而每个词语的 one-hot encoder 里面 1 的位置是不同的,所以被激活的向量 vx 就可以用来唯一表示 x。
词向量的维度与隐含层节点数一致,且一般情况下要远远小于词语总数 V 的大小,所以 Word2vec 本质上是一种降维操作
(!重点理解上面这段话!)
2. Skip-gram 更一般的情形
需要预测的上下文 y 有多个词时
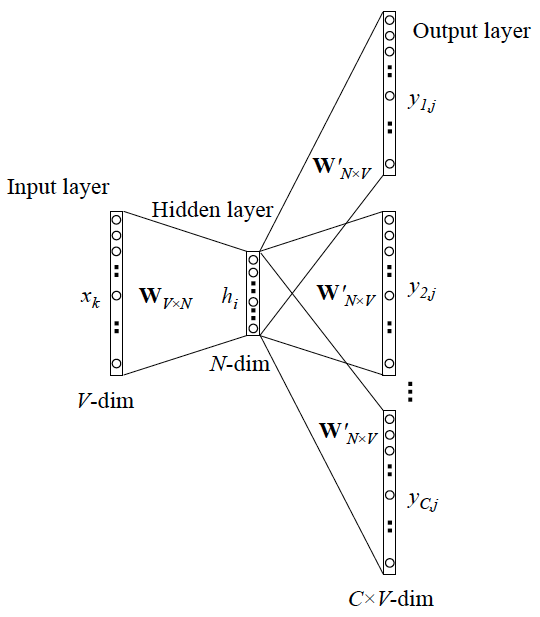
3. CBOW 更一般的情形
输入的上下文 x有多个词时