
TensorFlow 学习教程分享
- 莫烦大神的视频,他讲的比较浅,适合入门学习者
- https://blog.csdn.net/xierhacker/article/details/53103979
- cs20si
TensorFlow
1. 关于 TensorFlow 可以加速
TensorFlow提出的计算图概念,是为了更高效运行。计算图只是定义了变量以及相应的运算,但是不包含具体数据,只是在运行阶段再给计算图中的变量赋值并运算。好处是可以将复杂的运算放在Python外执行(可以调用高效的C代码实现),而 Python代码只是负责定义运算。
python外执行的理解:
很多函数 底层用别的语言实现,但是提供了Python函数接口。比如计算幂函数,Python的math库本身有pow函数,用Python实现,numpy的pow函数,用C实现,两个的计算速度不是一个量级。
2. TensorFlow 架构
参考博客:https://www.jianshu.com/p/667cbb20d802
(1)TensorFlow 的系统结构
ensorFlow 的系统结构以C API为界,将整个系统分为「前端」和「后端」两个子系统:
- 前端系统:提供编程模型,负责构造计算图
- 后端系统:提供运行时环境,负责执行计算图

(2)四个组件
Client
前端系统的主要组成部分,提供计算图的编程模型,支持多语言编程环境程模型
Client通以Session为桥梁,连接后端,启动计算图
Master
- 在分布式的运行时环境中,Distributed Master根据Session.run的Fetching参数,从计算图中反向遍历,找到所依赖的「最小子图」
- 然后,Distributed Master将该「子图」分裂为多个「子图片段」,以便在不同的进程和设备上运行「子图片段」
- 最后,Distributed Master将这些「子图片段」派发给Work Service,Worker Service成为「本地子图」
Worker
处理来自Master的请求
执行本地子图
协同任务之间的数据通信
Worker Service派发OP到本地设备,执行特定的Kernel。它将尽最大可能地利用多CPU/GPU的处理能力,并发地执行Kernel
Kernel
每一个OP根据设备类型都会存在一个优化了的Kernel实现,运行时根据本地设备的类型,为OP选择特定的Kernel实现,完成OP的计算
3.多语言编程
tensorflow 使用 bazel 进行自动化编译管理
在编译之前需要启动 Swig :Swig是一种让脚本语言调用C/C++接口的工具
Swig通过tf_session.i自动生成了两个文件:
pywrap_tensorflow.py:对接上层Python调用pywrap_tensorflow.py模块首次被加载时,自动地加载_pywrap_tensorflow.so的动态链接库。从而实现pywrap_tensorflow.py到pywrap_tensorflow.cpp的对应函数调用pywrap_tensorflow.cpp:对接下层C实现在
pywrap_tensorflow.cpp的实现中,静态注册了一个函数符号表,按照Python的函数名称,匹配找到对应的C函数实现,最终转调到c_api.c的具体实现

4. TensorFlow 的缺点
TensorFlow想要动态修改计算图比较困难。比如训练机器翻译或者聊天机器人的模型,句子长度不一样,计算图其实是不一样的。TensorFlow发布了一个工具,TensorFlow Fold,可以相对方便的动态修改计算图。不过总的来说,TensorFlow在计算图的设计灵活性上还是有些欠缺。
一、Graph和Session
TensorFlow的程序一般分为两个部分:
- 构建计算图
- 运行计算图
(一)Graph
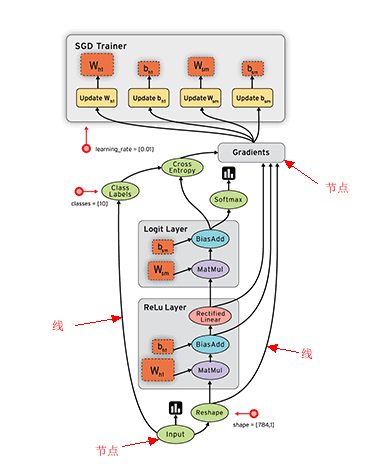
TensorFlow 使用Graph(数据流图)来描述计算的过程。而图必须在会话里被启动,会话将图的节点op使用特定的Kernel实现,分发到诸如 CPU 或 GPU 之类的设备上, 同时提供执行 op 的方法。
执行结果:
在 Python 中, 返回的 tensor 是 numpy ndarray
在 C 和 C++ 语言中, 返回的 tensor 是 tensorflow::Tensor
一旦开始任务,就已经有一个默认的图已经创建好了。而且可以通过调用tf.get_default_graph()来访问,只需要添加操作到默认的图里面,也可以新建一个图,向里面添加操作。
1 | g = tf.Graph() #创建新的graph |
(二)会话
PS:会话启动图的两种方法 Session 和 InteractiveSession
1. Session
1.将指定的图投放到session里
tf.Session.__init__(target=”, graph=None, config=None)
2.运行节点操作(op)得到tensor
tf.Session.run(fetches, feed_dict=None, options=None, run_metadata=None)
- fetch:需要取出来的tensor
- feed:需要传入的tensor
3.session不再用的话,就要调用 sess.close() 函数来释放资源,或者更方便的方法,也可以用上下文管理器
2. InteractiveSession
1.InteractiveSession 代替 Session 类,避免使用一个变量 sess 来持有会话
2.代替的原理:tf.InteractiveSession() 加载它自身作为默认构建的session,而 tensor.eval()和 operation.run() 取决于默认的session
3.代替 Session.run() 的操作
tensor的操作使用:tensor.eval()
op的操作使用:operation.run()
二、变量、常量、placeholder
(一)类
1.Tensor
- 零阶张量为 标量 (scalar) 也就是一个数值. 比如
[1] - 一阶张量为 向量 (vector), 比如 一维的
[1, 2, 3] - 二阶张量为 矩阵 (matrix), 比如 二维的
[[1, 2, 3],[4, 5, 6],[7, 8, 9]] - 还有 三阶 三维的 …
tensor里面并不负责储存值,想要得到值,得去Session中run,所以需要构造了一个Session的对象用来执行图sess=tf.Session() 。
得到Tensor的值:
1 Seesion.run()
2 t.eval(session=sess) t是Tensor的名字,session=sess属于的会话
2.Variable
变量需要初始值 (特别重要:变量的初始化)可以是一个任何类型任何形状的Tensor,值可以通过assign一个tensor来改变变量。
(二)函数
1.constant()
创建一个常量tensor
2.placeholder()
placeholder的作用为占个位置,不知道具体值,但是知道类型和形状等等一些信息,然后用feed的方式来把这些数据“填”进去。
PS:我的理解,需要定义变量是变量,常量是常量。变量、常量、placeholder都是tensor,只是用于网络中的不同地方。
三、shape 形状
tf.shape() —— tensor的形状
tf.size() —— 元素的总数
tf.reshape() —— 改变tensor的形状
tf.reduce_sum(input_tensor, reduction_indices=None, keep_dims=False, name=None)
计算tensor的某个维度上面元素的和,缩减维度
tf.reduce_mean(input_tensor, reduction_indices=None, keep_dims=False, name=None)
计算tensor的某个维度上面元素的平均值,缩减维度
维度:几层括号
轴axis:多维数组的索引
举个例子 :三维数组 a=[ [[1,2], [3,4]], [[5,6], [7,8]] ]
a[0]= [[1,2], [3,4]]
a[0,1,0]=3
四、随机数
主要用于网络权重初始化
1.正态分布填充得到tensor
tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
var = tf.Variable(tf.random_normal([2, 3], mean=-1, stddev=4))
2.均匀分布的随机数
tf.random_uniform(shape, minval=0, maxval=None, dtype=tf.float32, seed=None, name=None)
3.将第一维度重新洗牌
tf.random_shuffle(value, seed=None, name=None)
五、读取数据
程序读取数据一共有3种方法:
1.预加载数据
将数据直接内嵌到Graph中(在Graph创建constant),再把Graph传入Session中运行
2.供给数据 feed
用占位符替代数据,待运行的时候feed_dict填充数据
PS:上面两种方法的效率很低
3.从文件读取数据
不同的文件格式:
(1)CSV文件
(2)二进制文件
(3)图像文件
(4)TFRecords文件: TFRecords 数据文件是一种将图像数据和标签统一存储的二进制文件
https://blog.csdn.net/m0_37407756/article/details/80672192
六、队列和线程
对应上一节的 从文件读取数据 ,不过是多线程
PS:我就把它简单看作多线程的并行,每个线程占用一个CPU,不考虑并发
为什么需要多线程?
深度学习的模型训练过程往往需要大量的数据,而数据读取涉及磁盘操作,速度慢。Tensorflow 的计算主要使用CPU/GPU和内存,速度快。因此通常会使用多个线程读取数据,然后使用一个线程计算数据。
https://blog.csdn.net/chaipp0607/article/details/72924572
(一)队列
队列是为了数据读取的有序性
操作队列的函数主要有:
FIFOQueue()——创建一个先入先出(FIFO)的队列
RandomShuffleQueue()——创建一个随机出队的队列
enqueue_many()——初始化队列中的元素
dequeue()——出队
enqueue()——入队
1.FIFOQueue : 先入先出的队列
循环神经网络能够记住样本的先后次序,所以希望读入的训练样本是有序的
在使用循环神经网络时,希望读入的训练样本是有序的,就要用到FIFOQueue
2.RandomShuffleQueue:随机队列
使用CNN的网络结构,训练图像样本时,希望可以无序的读入训练样本
(二)线程
tensorFlow提供了两个类来帮助多线程的实现,从设计上这两个类必须被一起使用。
Coordinator 协调器,协调线程间的关系
QueueRunner 队列管理器, 用来协调多个线程同时将多个张量推入同一个队列中
七、模型保存
1.Saver
saver 的使用:https://blog.csdn.net/u011500062/article/details/51728830
2.checkpoints文件
Checkpoints文件是一个二进制文件,它把变量名映射到对应的tensor值
Saver类提供了向checkpoints文件保存和从checkpoints文件中恢复变量的相关方法
为了避免填满整个磁盘,Saver可以自动的管理Checkpoints文件,可以指定保存最近的N个Checkpoints文件
3.生成的文件
.meta文件保存了当前图结构
.index文件保存了当前参数名
.data文件保存了当前参数值
注意:
如果不给tf.train.Saver()传入任何参数,那么saver将处理graph中的所有变量。其中每一个变量都以变量创建时传入的名称被保存。
可以创建多个saver,来保存和恢复模型变量的不同子集,同一个变量可被列入多个saver对象中
如果仅在session开始时restore模型变量的一个子集初始化变量,你需要对剩下的变量执行初始化
有时候在检查点文件中明确定义变量的名称很有用,特别是,仅保存和恢复模型的一部分变量时。比如,训练得到一个模型,其中有个变量命名为"weights",想把它的值恢复到一个新的变量"params"中,这时变量的名称很有用。
八、神经网络”组件”
(一)激活函数
常用的激活函数 https://blog.csdn.net/xierhacker/article/details/71524713
tf.nn.relu
tf.nn.dropout
tf.sigmoid
tf.tanh
(二)损失函数
- tf.nn.softmax —— 用于多分类
tf.nn.softmax_cross_entropy_with_logits ——logits=W*X+b和labels=y 之间计算softmax交叉熵
交叉熵(Cross Entropy) :是Loss函数的一种,用于描述模型预测值与真实值的差距大小。交叉熵是正的,并且当输入$x$的输出越接近期望输出$y$的话,交叉熵的值将会接近0
逻辑回归的loss function:
$$
C=−1n∑x[ylna+(1−y)ln(1−a)]
$$
四种交叉熵函数 http://dataunion.org/26447.html
(三)优化器Optimizer
优化器是为了加快训练的速度,基于学习效率learning rate的改变 (注意:学习效率的改变,使得每种方法走过的loss的路径都是不一样的)
Optimizer
GradientDescentOptimizer
AdagradOptimizer
AdagradDAOptimizer
MomentumOptimizer
AdamOptimizer
FtrlOptimizer
RMSPropOptimizer
class tf.train.Optimizer 是基类,基本上不会直接使用这个类,一般使用子类 GradientDescentOptimizer 、MomentumOptimizer、AdamOptimizer
九、Timeline
Tensorflow的Timeline模块,可以记录会话中每个操作执行时间和资源分配及消耗的情况
生成方法 :
- 在需要查看的操作 sess.run() 加入 option和run_metadata参数,然后创建timeline对象,并写入到timeline.json
- 打开Google Chrome,转到该页面 chrome://tracing并加载该timeline.json文件
具体操作过程 https://walsvid.github.io/2017/03/25/profiletensorflow/
Timeline 的使用 https://www.jianshu.com/p/937a0ce99f56
十、TFDBG
TFDBG是 TensorFlow 的专用调试程序,借助该调试程序,可以在训练和推理期间查看运行中 TensorFlow 图的内部结构和状态
- TFDBG 的命令行接口(CLI)
- TFDBG的图形化用户界面(GUI):TensorBoard 调试插件